A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026
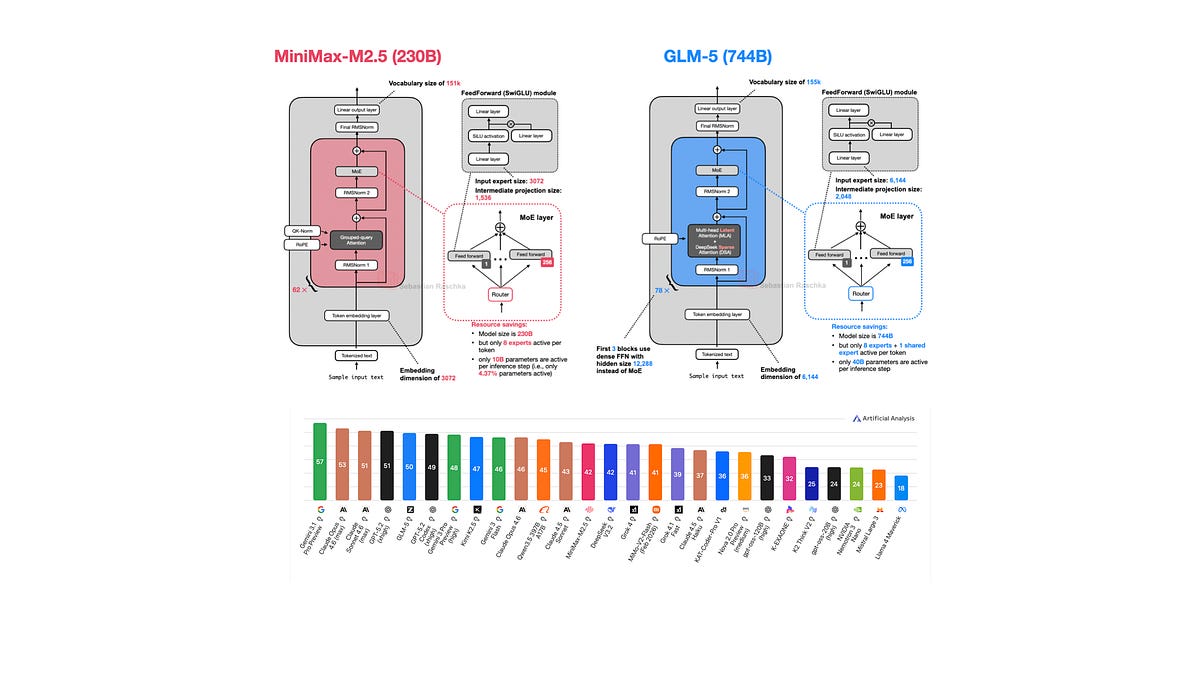
A Round Up And Comparison of 10 Open-Weight LLM Releases in Spring 2026
Read original article ↗This roundup is a highlight reel cut to hide the box score.
“Dream of Spring” sells vibes, but open-weight LLMs live or die on eval variance, token efficiency, and inference cost. Lumping 10 Jan-Feb 2026 architectures into one comparison without benchmark contamination controls is narrative cosplay, not analysis. If the piece doesn’t separate MMLU-Pro, SWE-bench, long-context recall, and throughput per watt, it’s grading smoke.
Show the deltas, or admit you’re just scouting by vibes.
Open-weight models bloom like plastic flowers in a data desert.
These ten architectures from 2026 chase benchmarks with sterile parameter counts and negligible narrative spark. Real intelligence demands grit under pressure not benchmarked regurgitation of training scraps. The analytics cult keeps optimizing what it can measure while gut-driven creation withers.
This spring dream is just another winter for soulful AI.
Ten open-weight models means our homegrown rookies are storming the billionaires' stadium.
I do not give a damn about parameter counts or fancy benchmark charts. I only care that open-source is finally scoring on the Silicon Valley suits. The big tech monopolies paid off the refs and hoarded the talent for years. Every local model is a massive middle finger to their rigged corporate paywalls.
Keep your subscription fees because the streets are taking the trophy.